Ligatures in the kana writing system
In the Japanese writing system, kana ligatures (Japanese: 合略仮名, Hepburn: gōryaku-gana) are ligatures in the kana writing system, both hiragana and katakana. Kana such as koto (ヿ; from 事) and shite (𬼀; from 為) are not kana ligatures, but polysyllabic kana. Most of such ligatures and polysyllabic kanas became obsolete.
Hardly any kana ligatures or polysyllabic kanas are represented in standard character encodings.
 Nobori
Nobori banners in sumo, using the yori ligature ゟ
These characters were widely used until a spelling reform decreed that each sound (mora) would be represented by one (kana) character. In January 1900, the Kana Investigation Committee (仮名調査委員) passed a resolution to "limit the number of homophone kana characters to one each" and aimed to abolish hentaigana, iteration marks, long-vowel marks, jionkanazukai [ja], the characters ゐ/ヰ (wi) and ゑ/ヱ (we), as well as the ligatures and the polysyllabic kanas.[1]
Kana ligatures such as  (toki),
(toki),  (koto), etc., were actively used in Japan during the Edo and Meiji periods. These ligatures were sometimes placed together along with the hiragana and katakana syllabaries in Japanese school textbooks.[2] Nowadays, these ligatures are obsolete and are not taught at schools anymore.[3]
(koto), etc., were actively used in Japan during the Edo and Meiji periods. These ligatures were sometimes placed together along with the hiragana and katakana syllabaries in Japanese school textbooks.[2] Nowadays, these ligatures are obsolete and are not taught at schools anymore.[3]
 讀方入門
讀方入門 (yomikata nyūmon), a school textbook in which
(koto) and
(toki) can be seen listed among the other kanas
[4]
These ligatures were not represented in computer character encodings until JIS X 0213:2000 (JIS2000) added ゟ (yori) and ヿ (koto). In 2002, ヿ and ゟ were added to Unicode 3.2. In October 2009, 𪜈 (tomo) was added to Unicode 5.2 in the CJK Unified Ideographs Extension C block. In June 2017, 𬼀 (shite), 𬼂 (nari), and 𬻿 (nari) were added to Unicode 10.0 in the CJK Unified Ideographs Extension F block.[5]
Polysyllabic hiragana
[edit]Polysyllabic katakana
[edit]
Character information
| Preview |
 |
 |
 |
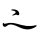 |
 |

|
| Unicode name
|
HIRAGANA DIGRAPH YORI
|
KATAKANA DIGRAPH KOTO
|
CJK UNIFIED IDEOGRAPH-2A708
|
CJK UNIFIED IDEOGRAPH-2CEFF
|
CJK UNIFIED IDEOGRAPH-2CF00
|
CJK UNIFIED IDEOGRAPH-2CF02
|
| Encodings |
decimal |
hex |
dec |
hex |
dec |
hex |
dec |
hex |
dec |
hex |
dec |
hex
|
| Unicode |
12447 |
U+309F |
12543 |
U+30FF |
173832 |
U+2A708 |
184063 |
U+2CEFF |
184064 |
U+2CF00 |
184066 |
U+2CF02
|
| UTF-8 |
227 130 159 |
E3 82 9F |
227 131 191 |
E3 83 BF |
240 170 156 136 |
F0 AA 9C 88 |
240 172 187 191 |
F0 AC BB BF |
240 172 188 128 |
F0 AC BC 80 |
240 172 188 130 |
F0 AC BC 82
|
| UTF-16 |
12447 |
309F |
12543 |
30FF |
55401 57096 |
D869 DF08 |
55411 57087 |
D873 DEFF |
55411 57088 |
D873 DF00 |
55411 57090 |
D873 DF02
|
| Numeric character reference |
ゟ |
ゟ |
ヿ |
ヿ |
𪜈 |
𪜈 |
𬻿 |
𬻿 |
𬼀 |
𬼀 |
𬼂 |
𬼂
|
Look up
合略仮名 in Wiktionary, the free dictionary.
- ^ "国立国会図書館デジタルコレクション". dl.ndl.go.jp. Retrieved 2 November 2025.
- ^ Sharko, Anna (2014). "Ligature as a common pattern of written character creation in Japan and Europe" (PDF). The Journal of Chinese Characters. 11: 151–166.
- ^ "小学校令施行規則 - Wikisource". ja.wikisource.org (in Japanese). 第十六条 (Article 16). Retrieved 2 November 2025.
- ^ "読方入門 (Editing Bureau of the Ministry of Education)" (PDF). 1884. pp. 5, 7. Retrieved 2 November 2025.
- ^ Unicode database. (Newly assigned in Unicode 5.2.0 [October, 2009] and in Unicode 10.0.0 [June, 2017])
- ^ a b c d 普通日本文典 Ochiai Naobumi et al., 1893
- ^ a b c d e f 和漢の文典 : 雅俗対照
- ^ a b c d e f g h 日本大文典. 第1編 p. 42–45 Ochiai Naobumi, 1894
- ^ a b ことばの泉 : 日本大辞典 (21版) p. 3 Ochiai Naobumi, 1904
- ^ "「参らせ候ふ」の意味や使い方 わかりやすく解説" [The meaning and usage of "参らせ候ふ" explained in simple terms]. www.weblio.jp. Retrieved 2 November 2025.
- ^ "まいらせ候". 漢字字躰帳 (in Japanese). 13 July 2025. Retrieved 2 November 2025.
- ^ Kōta Kodama's 『くずし字解読辞典〔普及版〕』 Tokyo-dō Publishing, among others, 1993
- ^ a b Ikudō Tajima's 「法華経為字和訓考—資料編(三)—」 Research Journal of the Faculty of Letters, Nagoya University, 1990
- ^ a b c d e f g h 國語學大系 第七巻 文字(一) p. 302–303 Kyūzō Fukui, 1939
- ^ a b c d e f g h 仮字本末 Nobutomo Ban, 1850
- ^ a b c d e 操觚便覧 Fujī Otome, 1899
 Nobori banners in sumo, using the yori ligature ゟ
Nobori banners in sumo, using the yori ligature ゟ
 讀方入門 (yomikata nyūmon), a school textbook in which
讀方入門 (yomikata nyūmon), a school textbook in which